Definitions
A
Algorithm
An algorithm is a procedure to accomplish a specific task, namely a well-specified problem, where the problem is specified by describing the complete set of instances it must work on and of its output after running on one of these instances. [23]
The distinction between a problem and an instance of a problem is critical. Determining that you are dealing with a general problem instead of an instance is your first step towards solving it. There are three desirable properties for a good algorithm. We seek algorithms that are correct, efficient, and easy to implement. Correctness may be formally verified by means of a proof (e.g., induction, contradiction, etc.) while efficiency is typically analyzed and established by means of Big- notation.
API wrapper
From Quora: An API-wrapper typically takes an API in one form and transforms it into another.
An example might be useful:
The main application interface to Flickr (the image hosting service) is a REST api (is http GET or POST calls). There is a library called pyFlickr which is a API-wrapper — it provides a Pythonic interface to Flickr — classes, methods, iterators using the REST API under the skin. It keeps all of the REST api methods intact and available, but you call them using Python function calls and wrappings.
Sometimes you will see the term binding, as in a Python binding for xyz; essentially this is different form of API-wrapper. Here the wrapper transforms an API designed for one programming language and provides functionality in a second language to call the original API. An example here is pyGTK. The original gtk api is written a a C library. pyGTK is called a Python binding for gtk as it allows a Python program to call the gtk API written in C.
Arithmetic sequence (math)
An arithmetic sequence is a sequence of the form
The number is the first term, and is the common difference of the sequence. The th term of an arithmetic sequence is given by
Arithmetic sequence partial sum
For the arithmetic sequence , the th partial sum
is given by either of the following formulas:
B
Big Oh
Controlled chaos: notation significantly simplifies calculations because it allows us to be sloppy — but in a satisfactorily controlled way. [10]
Abuse of notation: Donald Knuth notes in [10] that mathematicians customarily use the = sign as they use the word "is" in English: Aristotle is a man, but a man isn't necessarily Aristotle. Hence, in discussions of big oh, it is worth noting that the equality sign is not symmetric with respect to such notations; we have and but not , nor can we say that .
Need for and : As noted in [18], Big- notation is used extensively to describe the growth of functions, but it has limitations. In particular, when is , we have an upper bound, in terms of , for the size of for large values of . However, big- notation does not provide a lower bound for the size of for large . For this, we use big-Omega notation. When we want to give both an upper and a lower bound on the size of the function , relative to a reference function , we use big-Theta notation. Both big-Omega and big-Theta notation were introduced by Donald Knuth in the 1970s. His motivation for introducing these notations was the common misuse of big- notation when both an upper and a lower bound on the size of a function are needed.
The definition of below requires that every function in the set be asymptotically nonnegative: must be nonnegative whenever is sufficiently large. (An asymptotically positive function is one that is positive for all sufficiently large .) Consequently, the function itself must be asymptotically nonnegative, or else the set is empty. We therefore assume that every function used within -notation is asymptotically nonnegative. This assumption holds for the other asymptotic notations defined as well. [24]
The explanation above clarifies why other textbook authors (e.g., see [18]) sometimes write instead of just .
The definitions that follow may be found in [24].
Worst case (big-O)
An asymptotic upper bound may be described with -notation. Specifically, we use -notation to give an upper bound on a function to within a constant factor.
For a given function , we denote by the set of functions
A function belongs to the set if there exists a positive constant such that for sufficiently large . The following figure provides some intuition behind -notation:
For all values at and to the right of , the value of the function is on or below .
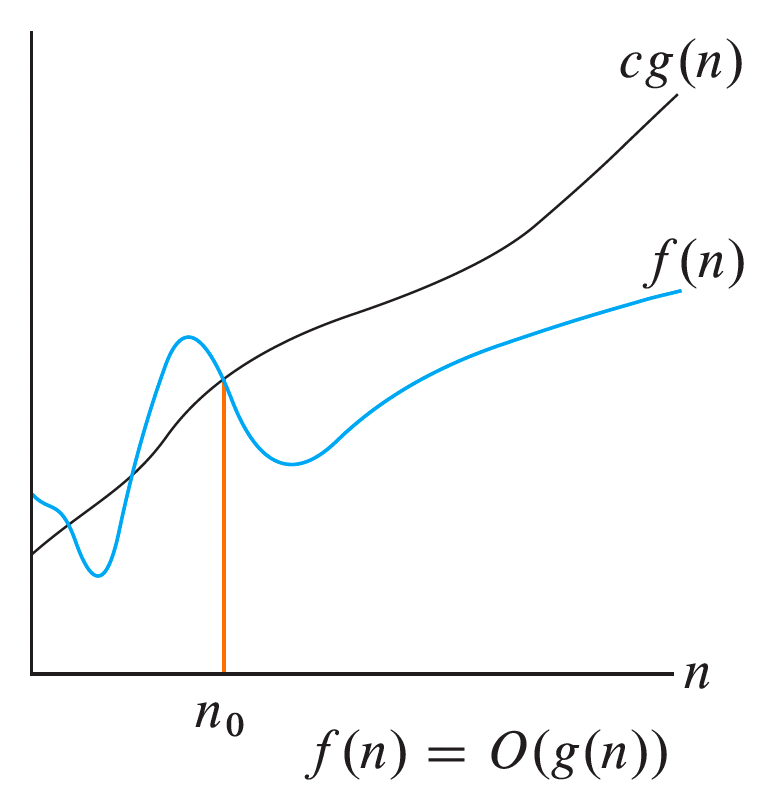
The definition above may be expressed more formally in the language of quantifiers as follows:
Best case (big-Ω)
Just as -notation provides an asymptotic upper bound on a function, -notation provides an asymptotic lower bound. For a given function , we denote by the set of functions
The following figure provides some intuition behind -notation:
For all values at or to the right of , the value of is on or above .

This definition may be expressed more formally in the language of quantifiers as follows:
Average case (big-Θ)
We use -notation for asymptotically tight bounds. For a given function , we denote by the set of functions
The following figure provides some intuition behind -notation:
For all values of at and to the right of , the values of lies at or above and at or below . In other words, for all , the function is equal to to within constant factors.

This definition, in light of the previous definitions for big- and big-, may be expressed more formally in the language of quantifiers as
where the notation above is meant to reflect the fact that is when is and is . With this in mind, we can let and reframe the quantified definition more succinctly:
C
D
E
F
G
Geometric sequence (math)
A geometric sequence is a sequence of the form
The number is the first term, and is the common ratio of the sequence. The th term of a geometric sequence is given by
Geometric sequence partial sum
For the geometric sequence , the th partial sum
is given by
Geometric series sum
If , then the infinite geometric series
has the sum
H
I
J
K
L
Logarithm results
- means
M
N
O
P
Path (graph theory)
A path is a trail in which all vertices (and therefore also all edges) are distinct.
Q
R
S
Summation results
Powers of integers
-
Sum of a unit times:
-
Sum of the first positive integers:
-
Sum of the squares of the first positive integers:
-
Sum of the cubes of the first positive integers:
T
Time-sharing (computing)
Time-sharing is the ability for multiple users to share access to a single computer’s resources.
An Ars Technica article on the history of Linux also mentions time-sharing: "Thus [due to costs associated with operating and owning the GE 645], there was widespread interest in time sharing, which allowed multiple researchers to run programs on the mainframe at the same time, getting results immediately on their remote terminals. With time sharing, the programs weren’t printed off on punch cards, they were written and stored on the mainframe. In theory, researchers could write, edit, and run their programs on the fly and without leaving their offices. Multics was conceived with that goal in mind. It kicked off in 1964 and had an initial delivery deadline of 1967."
Trail (graph theory)
A trail is a walk in which all edges are distinct.
U
V
W
Walk (graph theory)
A walk is a finite or infinite sequence of edges which joins a sequence of vertices.